LLMはドキュメントをどこまで読めるか ― Document VQAの性能検証
Summary generated by AI
- PDFはDocVQA、WordはBigDocs、PPTはSlideVQA、表混在はTAT-QAで、形式ごとに強みと限界が違う
- 人に対しGPT-4系はDocVQA87.4、SlideVQA57.3、TAT-QA79.7に留まり、構造理解で大差がある
- Excelは.xlsx内にXMLで数式や参照を保持し、見た目依存でなくXML直接解析が高精度回答に有効
はじめに
Document VQA (Visual Question Answering)とは、PDF/Word/PowerPoint/Excelなど文書の画像ファイルに対して自然言語の質問を投げると、文書内容に基づいて自動で答えを返す技術です。
表や図、レイアウト(段組み・見出し・欄外)など「ドキュメントならでは」の情報を踏まえて推論できるのが特徴です。
自然言語理解(NLP)、視覚情報処理(CV)、レイアウト解析を組み合わせることで、非構造な文書から機械可読できる情報を抽出・統合できます。これにより、契約書、社内報、財務諸表などの実務文書を、検索・分析・自動化に活用できるデータ資産へと転換することができます。
ただし、文書の形式(PDF/Word/PowerPoint/Excel)によって問題設定や有効な手法、評価の観点は大きく異なります。
本稿では、PDF/Word/PowerPoint/Excelの各文書形式に対するVQAの研究動向と評価ベンチマークを概覧し、その限界と課題を指摘します。
PDFに対するVQA
PDFは、「紙に印刷した時の見た目」をそのまま固定化したフォーマットであり、文字列だけでなくページ内の配置やレイアウト構造を正確に読み取ることが重要です。
代表的なデータセットであるDocVQAは、請求書・報告書・フォームなどのスキャン文書画像を対象に設計され、文書から質問への回答を導く能力を評価します。実社会に存在する視覚的ドキュメントがベースとなっており、OCRやレイアウト理解と連携することで、LLM単体よりも現実に近い課題に取り組めます。(図1)

図1: DocVQAにおけるタスク例
DocVQAでは質問を次のように整理し、モデルの多様な応答能力を測定します。
Extractive questions: 文書から該当箇所の文字列を抽出
Abstractive questions: 複数の情報を統合し、要約や書き換えで答える
Yes/No questions: 真偽を判定する簡潔な応答
ただし、表構造の厳密な復元や計算ロジックの追跡、図表の意味解釈といったタスクの評価には向きません。さらに設計上、単ページ中心であるため、長大文書や複数ページにまたがる照合・参照、ひいては文書全体の意図やストーリーの把握には不向きです。
こうした側面は、表・チャート特化データセットや複数ページ前提のベンチマークで補完する必要があります。
Wordに対するVQA
Word文書は、画像ベースのPDFと異なり、内部に構造化されたOffice Open XMLの論理構造を保持しています。見た目は整形された「ビジュアル文書」に見えても、その実体は「見出し」「段落」「表」「図表」などの論理的ブロック構造をXMLで表現する構造文書です。
したがって、Word文書に対するVQAは次のように2つのアプローチがあります。
ビジュアル重視
Wordファイルを画像化し、その視覚的レイアウトに基づいてVQAを行う配置依存の問い(図と本文の対応、ページ上の位置関係)に強いが、画像化やOCRのコストや誤りの影響を受けやすい。
テキスト構造重視(パース型)
Wordファイルのテキスト+構造情報(見出し階層・テーブル・リスト等)をパースし、得られたテキストや構造情報を基にQAを行う
BigDocsは、Wordを含む構造的長文ドキュメント(HTML, Markdown, LaTeX, Jupyter Notebookなど)を対象とした大規模な自然言語・コード・文書タスク向けデータセットです。Wordについては次の特徴を持ちます。(図2)
WordをHTMLベースに変換したうえで文脈理解・質問応答タスクを構成
見出しや段落、箇条書き、表などの構文構造を維持した文書テキストに対してLLMがQAを行う構成
文書全体の主旨理解、要点抽出、要約、分類といった意味理解に強い
このような形式では、Word文書の「内容そのもの(何が書かれているか)」についてのQAが可能になります。
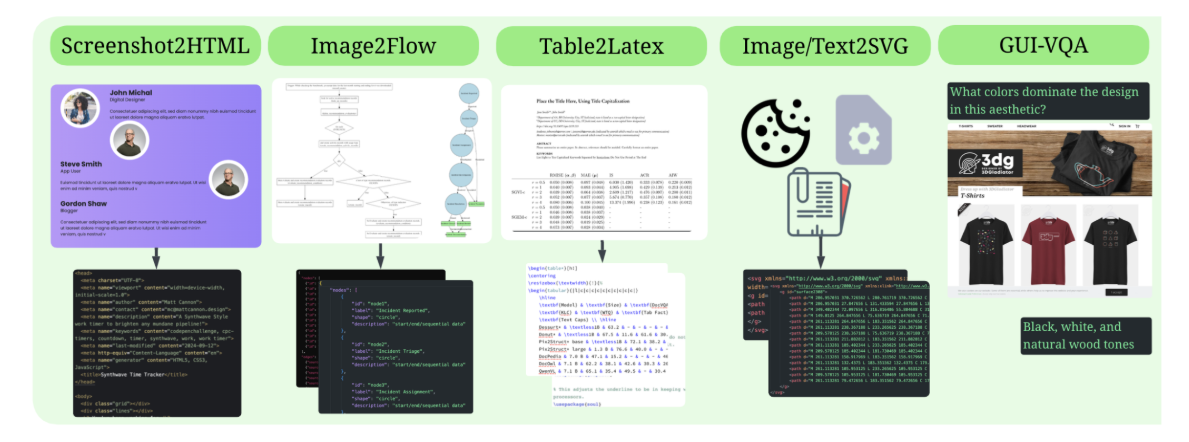
図2: BigDocsにおけるタスク例
一方で、BigDocsはWord内のテキスト情報に焦点を当てており、図表や画像、スタイル(太字・色・フォント)といった視覚的要素は保持されません。また、コメント/変更履歴、SmartArt、埋め込みオブジェクトも扱わないため、図とテキストの空間的な関係を理解することもできません。そのため、文書全体の意味理解には有効ですが、視覚レイアウトを含む質問には対応が困難です。
PowerPointに対するVQA
PowerPointは、複数のスライドで構成され、テキスト、図形、画像、表、アニメーションなど多様な視覚要素を内包するリッチな文書形式です。ドキュメント全体の情報を正確に理解するには、単一スライドではなく複数スライドをまたぐ関係性の理解が重要になります。
この観点を明確に評価できるベンチマークがSlideVQAです。このデータセットには次の特徴があります。(図3)
SlideVQAは、複数のスライドを対象に「どのスライドに関連情報があるか」をモデルが自ら判断し、質問に回答する設計となっています。質問の多くは、1枚のスライドでは完結しない情報理解を求めるもので、ドキュメント横断型の理解力が必要です。
質問は3カテゴリ(Exact Match, Multi-Hop Reasoning, Summary)に分かれており、単純な抽出だけでなく、複数スライド間の推論や要約が必要な問題も含まれています。
モデルが複数スライドから関連スライドを見つけ出し、情報を抽出・統合する能力が問われます。特に"Which slide shows..."や"What is the trend across slides?"のような問いに有効です。
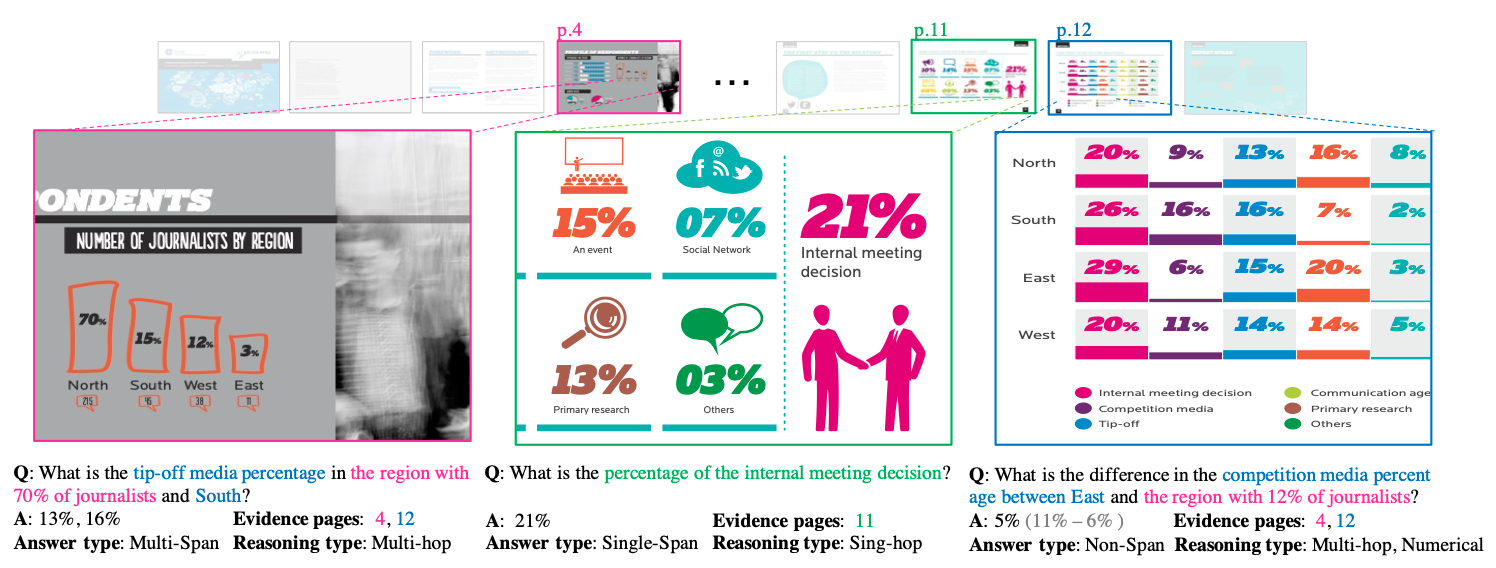
図3: SlideVQAにおけるタスク例
一方で、SlideVQAは静的なスライド画像を前提としており、アニメーション・遷移・ビルドは扱えません。特にSmartArtや矢印、吹き出しなど図解的構造は画像として存在しても、その構造的な意味(例:プロセス順序やフローダイアグラム)は読み取れません。
したがって、実務で利用される動的表現や関係構造の理解を問う設問には不向きで、スライド横断の内容抽出・要約に主眼が置かれます。
Excelに対するVQA
Excelは、表形式で構造化された数値・テキストデータを扱うドキュメント形式です。セルには計算式や参照が含まれることも多く、レイアウトやロジックを理解する必要があります。
このような背景のもと、TAT-QAは、表とテキストが混在するドキュメントに対するQAを目的としたベンチマークです。特に財務ドキュメント(収支報告書、決算概要など)を対象とし、数値計算と自然言語処理の融合を評価します。(図4)
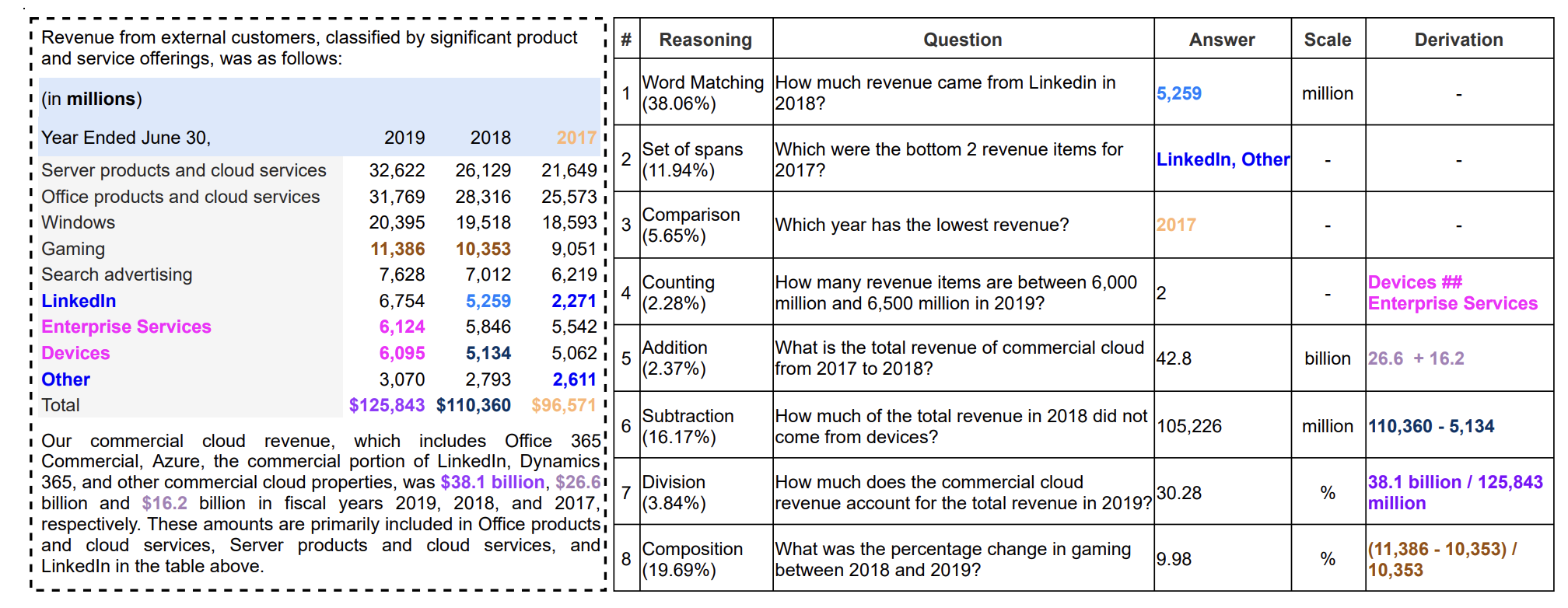
図4: TAT-QAにおけるタスク例
TAT-QAでは以下の評価が可能です。
表とテキストを統合的に扱う設計
計算を必要とするQAタスク
選択式・記述式の複合評価
一方で、TAT-QAは「財務系PDFのスキャン画像を模した表+テキスト構成」に特化しており、本物のExcelファイルが持つ多様性・動的機能は評価対象外となっています。
例:
=IF(),=VLOOKUP(),=INDIRECT()のような関数やマクロの評価なし複数シートにまたがるセル参照なし
条件付き書式やUI部品(ドロップダウン等)の取り扱いなし
ベンチマークデータセットにおける性能比較
ここでは、DocVQA、SlideVQA、TAT-QAという3つの主要なベンチマークにおける性能評価結果を示しています。
表1: 文書理解タスクにおける精度比較
手法 | DocVQA (ANLS×100) | SlideVQA (EM%) | TAT-QA (F1%) |
Human Performance | 98.1 | 89.8 | 90.8 |
GPT-4 Turbo with Vision | 84.6 | 55.1 | — |
GPT-4 Turbo + OCR | 87.4 | 57.3 | — |
GPT-4 (text, zero-shot) | — | — | 79.7 |
結果から、GPT-4系モデルを用いた場合でも、人間の性能との間に大きな差が存在することが明らかになりました。
特にSlideVQAタスクでは、GPT-4 Turbo with VisionとOCRを組み合わせた最良の構成でも57.3%の精度に留まり、人間の89.8%と比較して30ポイント以上の差が生じています。DocVQAにおいても、OCR統合により87.4という改善は見られるものの、人間性能の98.1には及びません。
これらの結果は、現在の視覚的アプローチやテキスト変換に依存した手法では、文書の構造的情報や数式、セル間の依存関係といった複雑な要素を十分に理解できていないことを示唆しています。
特にExcelファイルのような高度に構造化されたデータにおいては、表面的な見た目の解析では限界があり、XMLレベルでの構造解析が不可欠であることが示されています。
Officeドキュメントの情報を正確に取得するための手段
これまでのVQAや大規模言語モデル(LLM)によるExcel解析では、主に視覚的に表を読み取るアプローチ、あるいはテキスト変換後の推論に依存していました。しかし、Excelファイルの本質は「画像」や「テキスト」ではなく、構造化されたプログラム的データです。
特に.xlsx形式のExcelファイルは、ZIP圧縮された複数のXMLファイルから成り立っており、各セルやシート、数式、スタイル、参照関係、関数構文などが厳密に定義されたXML構造で保持されています。Galirageでは、これまでのようにExcelを画像や表の「見た目」から扱うのではなく、内部のXMLファイル群を直接読み解き、構文や関係性を把握することで、次のような精密な解析が可能になります。
数式の正確な評価
セル参照の依存関係解析
スタイル・色・条件付き書式の抽出
マクロや名前付き範囲の解析
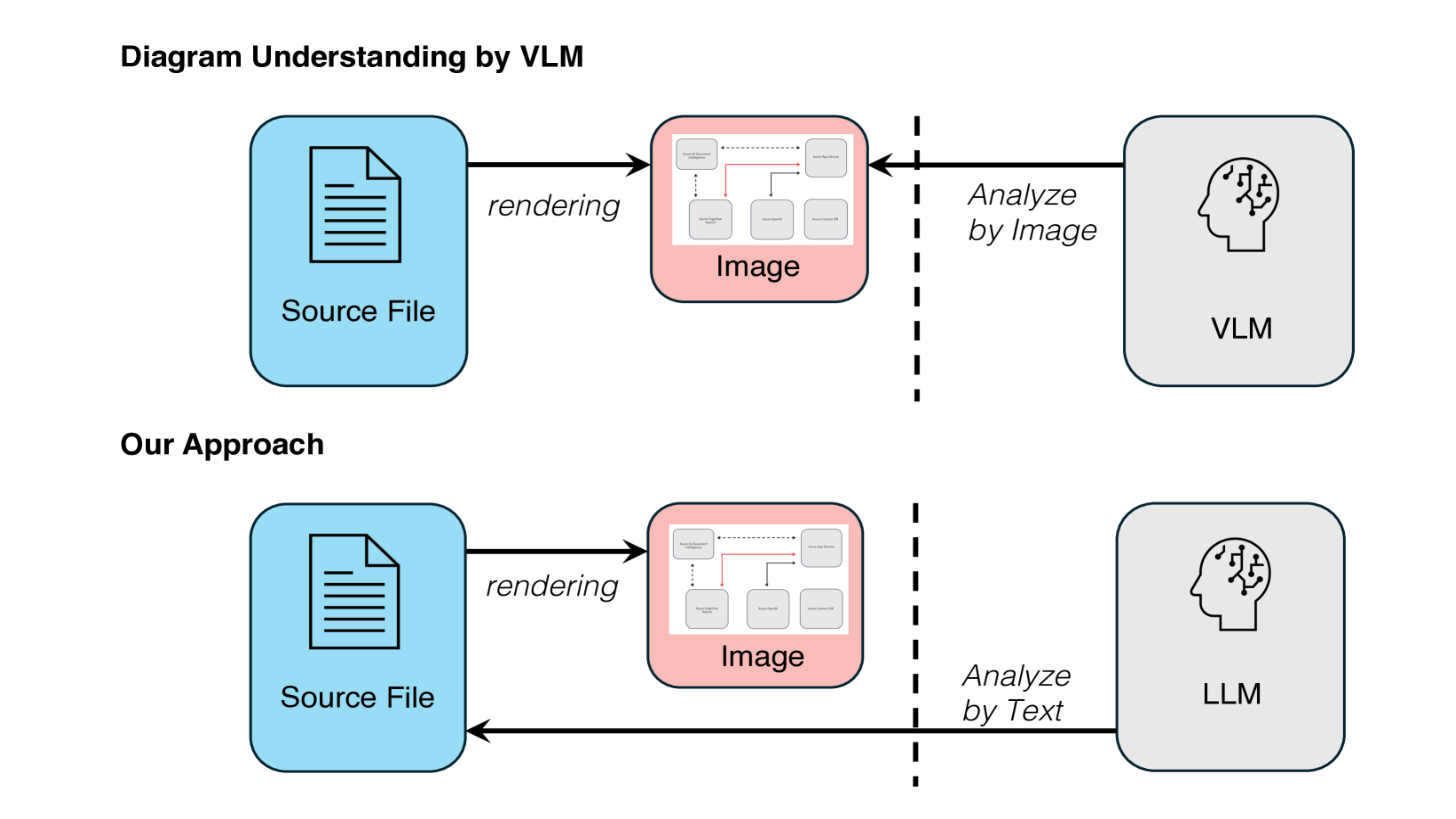
図5: ExcelのXMLを解析する場合の概念図
Excelは、単なる表計算ツールではなく、小規模なデータベース/計算エンジンとして機能する複雑な構造を持っています。その解析には、表の見た目に頼らず、構文・ロジック・構造情報を扱う必要があります。
GalirageのXMLパース技術は、こうしたExcelの本質的な情報構造を忠実に取得・可視化し、より深い質問への高精度な回答や、再現性のある結果の生成を可能にします。このようなアプローチは、将来的にはLLMとの連携によって、実務に耐えるExcelの読み取り・説明・修正支援にも応用できると考えられます。
より詳しい情報は下記の記事をご覧ください。
Galirageでは、本研究に関連する仕事の依頼を受け付けております。ページ末尾の「Contact Us」よりお気軽にお問い合わせください。」に変更をお願いします◎
FAQ generated by AI
文書画像に自然言語で質問し、文書内容に基づく答えを自動生成する技術です。
PDF、Word、PowerPoint、Excelの4形式です。
スキャン文書のQA能力を測りますが、表の厳密復元や複数ページ理解には不向きです。
画像化してレイアウト重視で問う方式と、XML由来の構造をパースしてQAする方式の2つです。
複数スライドから関連情報を見つけ出し、Exact/Multi-Hop/Summaryの3分類で評価します。