図表理解における視覚言語モデル(VLM)の課題と解決策
Summary generated by AI
- VLMの画像解析を避け、OfficeのXMLをJSON化してLLMへ入力する図理解手法を提案
- Excel図の関係抽出は提案手法12/12=100%、VLMは8/12=66%
- ライブラリspreadsheet-intelligenceをApache2.0で公開し、pptx/docx対応や複雑図面へ拡張予定
概要
Galirageでは、ビジネス文書に不可欠なシステム図・フロー図の関係構造を高精度に解析するため、Vision Language Model(VLM)が抱える限界に挑戦しています。
2025年に発表した論文「Overcoming Vision Language Model Challenges in Diagram Understanding」では、従来の「画像として読む」アプローチを転換し、ExcelやPowerPointなどOffice系ファイルのXMLメタデータを直接パースしてLarge Language Model(LLM)へテキスト入力する手法を提案しました。
実証実験では、VLMベースの画像入力方式に比べ図形識別と関係抽出の精度向上させ、図理解タスクにおける回答品質を改善しました。
既存アプローチ(画像ベースVLM)の限界
既存のVLMは、図をPNG/JPEGなどの画像に変換してから解析するワークフローを前提としています。しかし本論文の調査では、「画像として読ませる」処理が制約になっていることを明らかにしました。
まず、VLMは幾何学的な形状(矩形・円・曲線)を正確に言語化する能力が不足しており、この幾何認識がQAや推論タスクの律速になります。
さらに、装飾線が重なり合うレイアウトや多彩な配色を含む実務ドキュメントでは誤認識が急増し、複雑な図面ほどロバスト性が低下します。
加えて、図中の線で表現される要素間の関係を捉え切れず、事前学習知識との齟齬を埋め合わせようとして存在しないコネクタを生成してしまうハルシネーションも確認されています。
XMLを直接LLMに与える手法
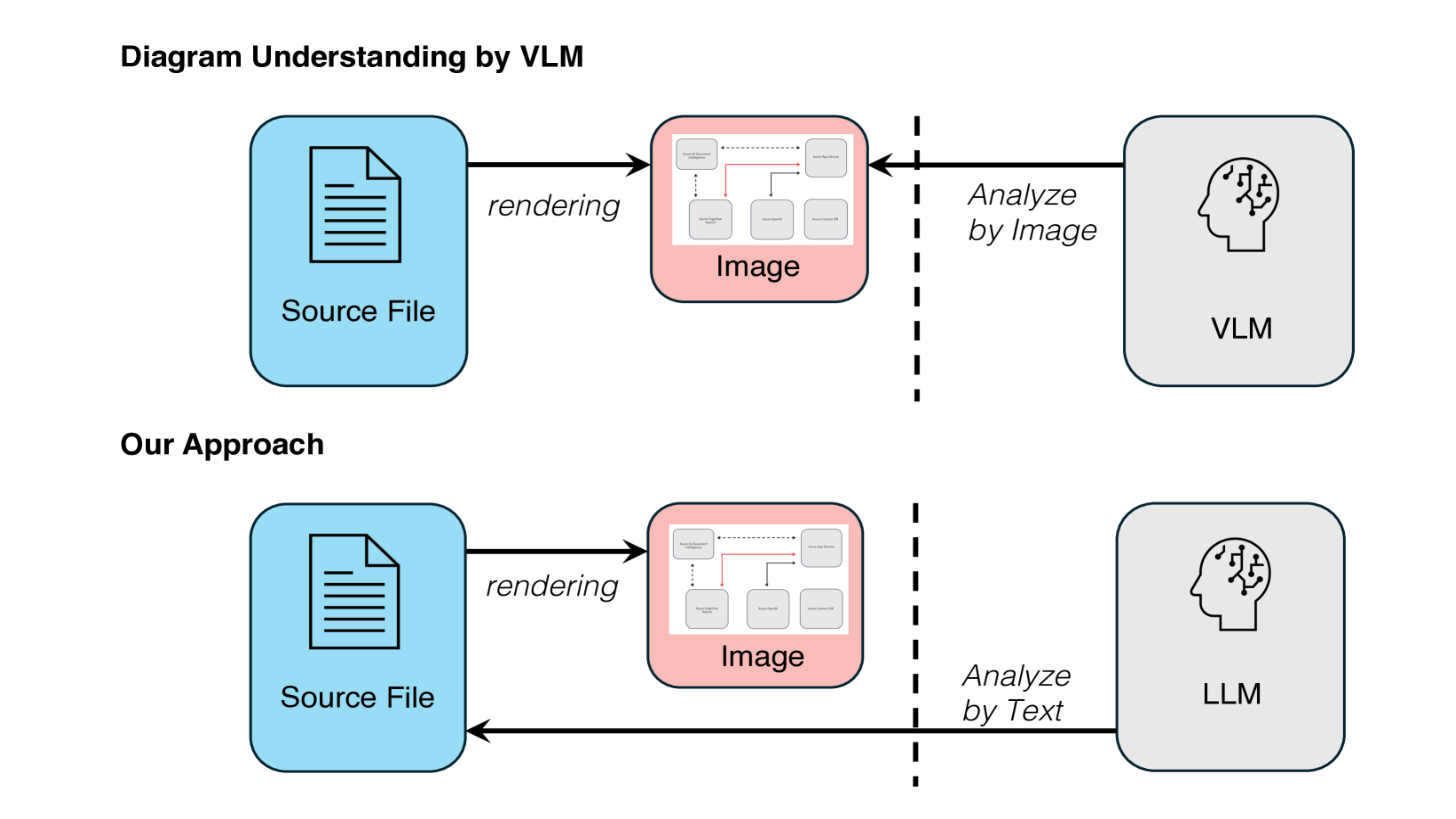
本研究では、図面を画像として解析する従来方式とは異なり、Office Open XML形式のソースファイルから図形情報を直接抽出し、それをLLMに入力するパイプラインを構築しました。(図1)
図1: 本手法はVLMの視覚認識に依存せず、図の情報はテキストとしてLLMに入力して解析します。描画に必要なグラフィック情報は、レンダリング時にソースファイルを参照します。
1. 図面の“生データ”を取り出す
ExcelやPowerPointなどのOfficeファイルは、内部でXMLがZIP圧縮された構造になっています。本研究では、このXMLから
形状ID
座標(回転・拡大縮小を補正済み)
塗り・線色
含まれるテキスト
を抽出し、JSON形式に正規化するライブラリspreadsheet-intelligenceを開発・公開しました。対象は日本の開発現場でよく使われるExcel版システム設計図です。(図2)
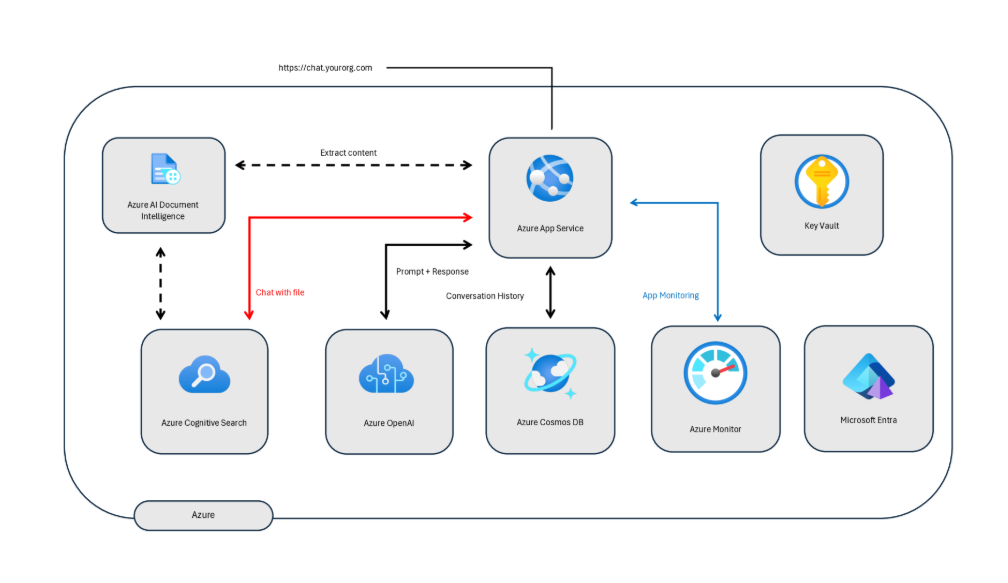
図2:本研究で使用された図は、Excel上で作成されたシステム設計図であり、矩形、テキストボックス、直線コネクタ、折れ線コネクタを用いて描かれています。
2. LLMが読みやすい形に整える
XMLそのままでは冗長なので、本研究では次の前処理を行っています。
前処理 | 目的 |
端点方位を上下左右で符号化 | コネクタがどの辺に接続するかを明示 |
色テーマ名→RGB変換 | 描画時の色を再現 |
グループ化情報をスキップ | 作成者ごとの表現差異の影響を抑制 |
こうして得た最小限のJSONを、そのままLLM(GPT-4o)へのプロンプトに組み込みます。(図3)

図3: 左側には、xlsxファイルから抽出した図形データのXML抜粋が示されています。生の数値や別名化された文字列が羅列されているため判読しづらく、しかも情報が複数ファイルに分散して冗長に含まれています。右側には、コネクタとシェイプに関する意味のある情報を解析・変換・要約したJSON形式が示されており、ダイアグラム理解とLLMへの入力に最適化されています。
3. GPT-4oで「線の行き先」を推論
モデルの推論では、画像を用いずに Office Open XML から抽出・正規化した図形・コネクタ情報(JSON)を GPT-4oに入力し、各コネクタの開始先(start)と終了先(end)を特定する手順を示します。座標は左上原点(x 右/y 下)で、回転・反転・拡大縮小は補正済み、端点方位は上下左右で符号化し、グループ情報は使用しません。
入力(LLM に渡す情報)
shapes:
id, shapeType, left, right, top, bottom, text, fillColor, borderColorconnectors:
id, type, startX, startY, endX, endY, StartArrowHeadDirection, EndArrowHeadDirection, arrowType, color必要に応じて、前段のエンティティ理解で得たコンポーネント一覧(図3)
方法
コネクタ端点の座標と方位を図形の境界(left/right/top/bottom)に照合し、接続候補を抽出します。
方位と対応辺の整合、および端点から辺までの距離に基づいて start/end を決定します。
近傍のテキストボックスがある場合は、コネクタの注釈(annotation)として関連付けます。
出力は
connector_id、start_shape、end_shape(必要に応じてannotation)とします。
プロンプト例 「Connector id=12 の start_shape と end_shape を答えてください。」(図4)

図4: 提案手法におけるプロンプトの例
実証結果
実際にXMLから抽出・整形した図形データを用いてLLMに図理解タスクを実行させ、従来のVLMによる画像ベース手法と比較した実証実験の結果を示します。対象となったのは、Excelで作成されたシステム設計図(図2)であり、構成要素として矩形、テキストボックス、直線/折れ線コネクタが含まれます。
エンティティ理解の精度
まずは、図に含まれるコンポーネント(矩形+テキスト)や注釈情報の認識精度を比較しました。
観点 | 提案手法 | VLM |
コンポーネント列挙 | 完全に再現(100%) | 完全に再現(100%) |
注釈テキスト抽出 | 正確に抽出 | 正確に抽出 |
矩形とテキストの対応付け | 座標一致から推定し、正確にペア化 | 見た目に基づく推定、精度は同程度 |
結果は、どちらの手法でも適切にエンティティを表現することができました。
関係抽出の精度
続いて、図中の要素同士をつなぐコネクタの関係把握について比較を行いました。以下のような直線/折れ線、注釈付きの多様なコネクタが対象です。(図5)
観点 | 提案手法 | VLM |
正しく抽出された接続関係 | 12/12(100%) | 8/12(66%) |
誤認識(存在しない関係を生成) | 0件 | 3件(ハルシネーション) |
検出漏れ | 0件 | 1件(特に短いコネクタ) |
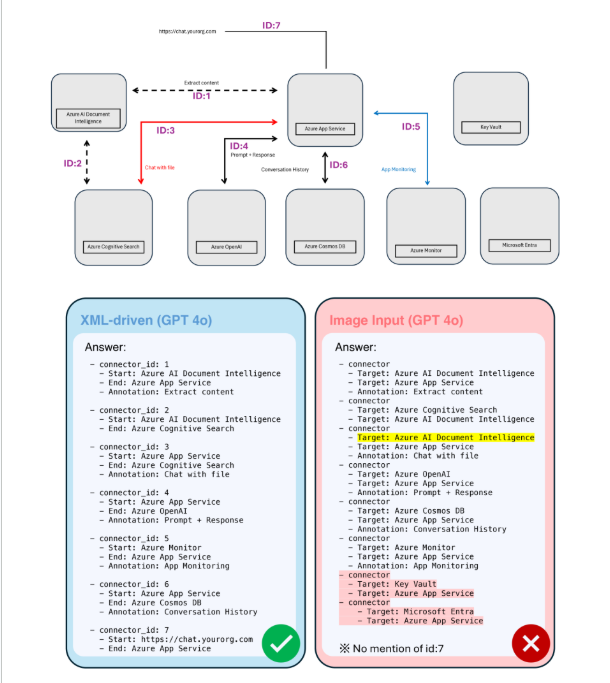
図5: 上図では、本提案手法が各コネクタの向きや接続先を正確に把握している一方で、画像ベース手法では曲線や折れ線の終点を誤認識し、存在しない接続(例:Key Vault ↔ Microsoft Entra)を生成しています。
コネクタは単なる線ではなく、「どの図形とどの図形をつなぐのか」という構造的関係を担っています。画像入力ではこの構造認識に誤差が生じやすく、特に折れ線や斜線の解析では視覚的ノイズによる誤認識が頻発しました。
対して、本提案手法では
コネクタのstart/end位置と向きを明示的に取得
接続先候補の図形座標と照合して推論
することで、一切のハルシネーションなく、論理的に正しい関係抽出が実現されました。
今後の展望
本研究で提案した「XMLメタデータを活用したLLMベースの図理解手法」は、VLMの限界を克服するひとつの有効なアプローチであることが示されましたが、さらなる実用化に向けて以下のような拡張・応用を目指しております。
1. Officeファイル形式の横展開
本研究は Excel(.xlsx)に特化して検証を行いましたが、業務現場ではPowerPoint(.pptx)やWord(.docx)などのOffice形式にも豊富な図形情報が含まれます。今後はXMLパース処理をこれらの形式へ拡張し、スライド・文書・ダイアグラムから抽出した図形・コネクタ・テキストを共通のJSONスキーマへ正規化することを目指します。これにより、会議資料や要件定義書に含まれる図面の理解を自動化でき、文書種別をまたいだ関係抽出やレビューの効率化、変更差分の追跡および根拠トレースが容易になります。結果として、社内文書全体への汎用性が高まり、より包括的で再現性と監査性に優れたビジネス文書解析を実現します。
2. 複雑な実務図面への対応
実務ではSmartArtやOffice図形複雑なグループ構造、レイヤー構成を持つ図が一般的で、形式上はOffice図形であっても構造抽出が難しく、現行手法では解析対象外となっています。
今後は、階層や連結の正規化ルールを整備することで、曖昧な複合オブジェクトや任意グルーピングにも対応できるようにし、より複雑な図面への適用範囲の拡張を探求していきます。これにより、解析の再現性と網羅性を高め、実務図面に対する堅牢な理解を実現します。
これらの展望により、LLMを中心とした図理解技術は「視覚から構造への転換」というパラダイムを超えて、実際のビジネス活用へと進化することが期待されます。Galirageでは今後もオープンソースライブラリと実運用フィードバックを軸に、より柔軟で拡張性の高いアーキテクチャを模索していきます。
おわりに
本研究では、ビジネス文書に含まれる図解の構造をより正確かつ論理的に理解するための新たなアプローチとして、VLMに依存しない「XMLによる図理解」の手法を提案・検証しました。具体的には、ExcelやPowerPointなどのOffice文書に含まれるXMLメタデータを直接抽出し、整形されたJSONをLLMに入力することで、図形や関係構造の理解精度を大幅に改善することができました。
従来の画像ベースの解析では避けがたかった**誤検出やハルシネーション(存在しない関係の生成)**も、構造情報を直接扱うことによって完全に回避され、実務ドキュメントを対象とする図理解タスクにおける現実的な精度と再現性が確認できました。
また、本研究で開発したXMLパース・図形情報抽出ライブラリは、spreadsheet-intelligenceとしてApache2.0ライセンスで公開しており、他のOffice形式(.pptxや.docx)への適用や、対応するオブジェクトの拡張も目指していきます。
本研究および実装にご関心のある方は、次のリソースもぜひご覧ください。
論文:
Overcoming Vision Language Model Challenges in Diagram Understanding
ライブラリ:
実験コード:
Galirageでは、本研究に関連する仕事の依頼を受け付けております。ページ末尾の「Contact Us」よりお気軽にお問い合わせください。」に変更をお願いします◎
FAQ generated by AI
VLMの限界を越えてシステム図・フロー図の関係構造を高精度に解析することです。
Office Open XMLから図形情報を抽出し、整形したJSONをLLMに直接入力する方法です。
案手法は12/12(100%)で、VLMは8/12(66%)でした。
Excelのシステム設計図を対象とし、複雑なグループ構造などは現行手法では解析対象外です。
ページ末尾の「Contact Us」から依頼や問い合わせができます。