
プロダクションコードと設計書の差異検出の手法
Summary generated by AI
- 設計書とコードの乖離は保守性低下や契約リスクを招く深刻な問題であり、LLMを用いた意味的な比較で自動検出が可能になった
- CursorなどのAIエディタやRAG・チャンキング技術を活用し、関数定義の整合性からロジックの振る舞いまで段階的に検証できる
- CI/CDパイプラインへの組み込みにより、プルリクエスト時に設計書との乖離リスクを自動検出するDocOpsワークフローが構築できる
はじめに
現代のソフトウェア開発、とりわけウォーターフォールモデルなどの開発プロセスを採用している大手SIerの現場において、現場で運用されているプロダクションコードと設計書(基本設計書・詳細設計書など)の内容が一致していないという問題は、古くて新しい問題といえます。
設計書に基づいてコードを書いているはずなのに、いつの間にか実際に動いているコードと設計の内容が食い違っている箇所がいつの間にかポツポツ現れている、という場面に遭遇したことのある方は多いはずです。
この乖離は、単なる「ドキュメントの更新忘れ」という軽微な問題にとどまりません。保守フェーズにおいて、エンジニアが影響範囲調査を行う際、設計書を信頼できず、結局ほぼすべてのソースコードを読み解くという非効率な作業を強いられます。 さらに深刻なのは、受託開発におけるユーザー企業との信頼関係への影響です。 「設計書通りに作られていない」という事実は、瑕疵担保責任や契約不履行のリスクを孕んでおり、システム障害発生時の原因究明を遅らせる要因ともなります。
本レポートでは、この深刻な課題に対し、生成AI(LLM)や最新のコードエディタ技術を応用して、効率的かつ高精度に差異を検出する具体的な手法について論じます。
設計書の更新漏れと実装ミスが発生する根本原因
なぜ、厳格なプロセスを敷いているはずの組織でもドキュメントの乖離が発生するのでしょうか。その根本原因をまずは見ていきましょう。
実装時に発見・修正された問題が設計に反映されない
詳細設計書がいかに精緻に書かれていても、実装段階で初めて判明する技術的な制約や論理的矛盾は必ず存在します。 開発者は「納期」というプレッシャーの中で、まずコードを修正し、動く状態にすることを最優先にしがちです。このとき、「コードは修正したが、設計書の修正は後回し」となることがしばしば発生し、結果としてそのタスクが永久に忘れ去られがちです。 特に、設計書がExcelやWordなどで管理されており、コード(Git)と別リポジトリにある場合、このコンテキストスイッチのコストが更新の心理的障壁となります。
仕様変更時のドキュメント更新漏れ
開発中盤以降の仕様変更も大きな要因です。 顧客からの急な仕様変更依頼が、メールやチャット(Slack/Teams)、あるいはチケット管理システム(Jira/Redmine)上のやり取りだけで完結してしまうケースです。 現場リーダーは「とりあえず実装に反映して」と指示を出し、マスタとなる設計ドキュメントへの反映プロセスがスキップされます。 結果、「正しい仕様」がドキュメント上ではなく、チャットログやチケットの中に散逸し、誰も全容を把握できない状態に陥ります。
コードと設計書の差異検出のアプローチ
従来、この差異検出は「目視レビュー」や「納品前の突合点検」という人海戦術に頼っていました。 しかし、数万行〜数十万行のコードと数百ページのドキュメントを目視で比較することはとても手間がかかりますし、現実的でないケースも多々有ります。
また、diffコマンドのような単純なテキスト比較ツールは役に立ちません。設計書は自然言語(日本語)で書かれ、コードはプログラミング言語で書かれているため、表現形式が根本的に異なるからです。
ここで有効なのが、大規模言語モデル(LLM)を用いた意味的(セマンティック)な比較です。アプローチは大きく分けて、「構造的な整合性チェック」と「論理的な意味の比較」の2段階で考えることができます。
関数名・クラス定義の整合性チェック
まず最初に行うべきは、比較的低コストで実行可能な「構造的な整合性チェック」です。これは、詳細設計書に定義された「クラス名」「関数名(メソッド名)」「引数」「戻り値」が、実際にコード上に存在するかを検証するフェーズです。
AIエージェント(Cursor等)の活用
現在、VS Codeをフォークして作られたAIコードエディタである Cursor などのツールが非常に有効です。Cursorには Codebase Answers という機能があり、ローカルのコードベース全体をコンテキストとしてAIに質問を投げることができます。
例えば以下のような趣旨のプロンプトをCursorのChatに投げるだけでOKです。
具体的なプロンプト例:
このプロジェクトの設計書とソースコードの差分を検出したいです。具体的には設計書にある関数名やクラス定義が、現在のコードベースに存在するか確認してください。存在しないもの、あるいは名称が微妙に異なるものをリストアップしてください。今回、実際に手元で設計書と実装をわざと乖離させた小規模なプロジェクトを作成して、Cursorで差分を検出してみました。 その上で、設計と実装の矛盾点を抽出したところ、下記のように矛盾点をリストアップしてくれました(想定していた矛盾点は全て網羅されていました)。
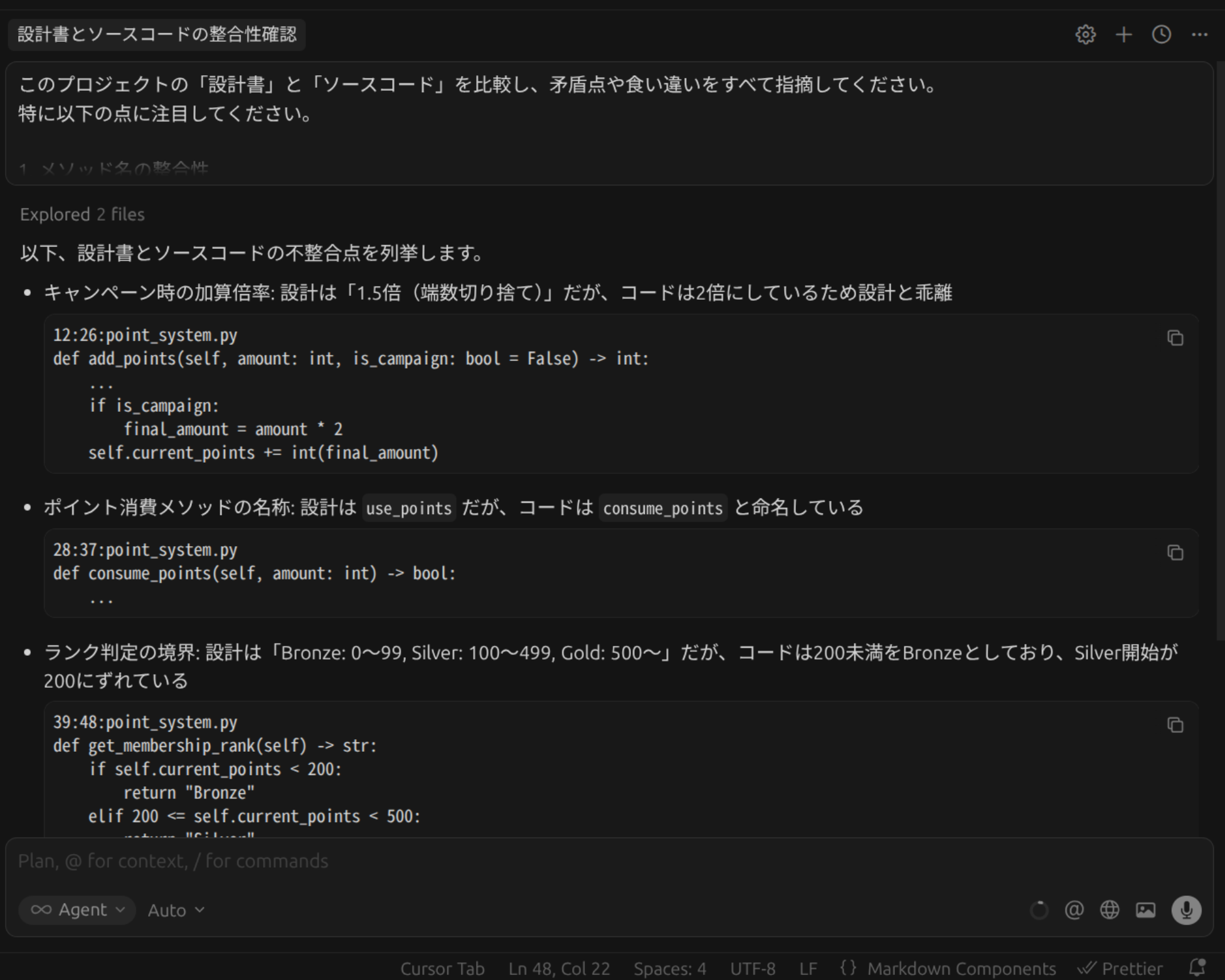
しかも今回は、コードの関数名といった矛盾箇所だけでなく、これから述べるコードの振る舞いと設計の矛盾に関する点までリストアップできていました。 このように、設計と実装の差分を検出するという観点において、CursorなどのAI開発エージェントツールは非常に有用です。
裏側の技術:RAGとキーワード検索のハイブリッド
Cursorなどのツールは、裏側で以下の処理を行っていることが多いです。
キーワード検索(grep的な処理): 正確な関数名の一致などを高速に探します。
ベクトル検索(Vector Search): コードの意味的なまとまりをベクトル化してインデックスを作成しており、関連するファイルを検索してLLMのコンテキスト(プロンプト)に挿入しています。
これにより、開発者はファイルを開いて確認する手間なく、設計書に書かれた「物理的な定義」の有無を即座に判定できます。
設計とコードをLLMのプロンプトに乗せて比較する
構造的なチェックが終わったら、次は本丸である「ロジック(振る舞い)」の整合性確認です。設計書に「Aの場合はBの処理を行い、Cの場合はエラーとする」と書かれているロジックが、コード上で正しく実装されているかを検証します。
コンテキストウィンドウに収まる場合(小規模)
比較対象の機能が小さく、設計書のテキストと関連コードを合わせてもLLMのコンテキストウィンドウに収まる場合は、単純に両方をプロンプトに入力するのが最初に試すべきアプローチです。
プロンプト例:
上記は「機能Xの設計書」で、下記は「機能Xのソースコード」です。設計書に記載されているロジックと、実際のコードの挙動に矛盾がある箇所を指摘してください。特に条件分岐の境界値やエラー処理に注目してください。分量が多すぎる場合の対処法(大規模)
実際のエンタープライズ開発では、設計書もコードも膨大であり、一度にプロンプトに入れることは不可能です。また、コンテキストが長すぎるとLLMの推論精度が低下する現象も発生します。 これに対処するためには、チャンキング(Chunking) と 高度な検索戦略 を組み合わせる必要があります。
1. チャンキング(Chunking)の実践
ドキュメントやコードを適切なサイズに分割する技術です。
設計書のチャンキング: 単に文字数(例:1000文字ごと)で切ると文脈が切れるため、見出し単位や段落単位で分割します。LangChain などのライブラリにある
RecursiveCharacterTextSplitterなどを使用し、セパレータとして改行やMarkdownのヘッダーを指定するのが一般的です。コードのチャンキング: こちらはより注意が必要です。文字数で切ると関数定義が分断されます。LangChainの
Language.PYTHONやLanguage.JAVAなどの指定ができるスプリッターを使用し、クラスや関数単位で意味のまとまりを保持したまま分割します。
2. 比較・検証のアルゴリズム
チャンク化したデータをどう比較するか、いくつかの手法があります。
A. ベクトル検索(RAGアプローチ)
設計書の各チャンク(仕様の断片)をクエリ(質問)として、ベクトルDB化されたコードベースから「関連するコード」を検索(RAG:Retrieve)します。
プロセス:「設計書Chunk Aに関連するコードを探して」→「見つかったCode Chunk X, Yと比較して」とLLMに指示。
メリット:高速でコスト効率が良い。
デメリット:検索漏れが発生すると検証できない。
B. 機械的な総当たり
設計書チャンクとコードチャンクの全ての組み合わせを検証する、二重ループのアプローチです。
メリット:網羅性が高い。
デメリット:APIコストと時間が爆発的に増えるため、現実的ではないことも多い。
C. Map-Reduce / 要約ベース比較
まずコードの各チャンクをLLMに読ませ、「このコードは何をしているか」という「要約仕様書(中間データ)」を生成させます(Map)。 次に、その「生成された要約」と「元の設計書」を比較します(Reduce)。
メリット:自然言語同士の比較になるため、精度の高い比較が可能。コードの詳細な実装(変数名など)に惑わされにくい。
コードからの逆設計(リバースエンジニアリング)と差分抽出
一旦、「コードこそが正(Truth)」とし、コードからドキュメントを生成し、生成されたドキュメントと元の設計書などを比較するアプローチをとることも可能です。
手法
コード解析: 対象のソースコードを読み込ませ、LLMに設計書(Markdown形式など)を出力させます。
構造化: 出力形式として、自然言語だけでなく、Mermaid記法(フローチャートやシーケンス図)を指定することで、可視化されたドキュメントの生成が可能です。
ギャップ分析: 本来あるべき(と想定される)仕様のメモや、古い設計書がある場合、この「AI生成された現在の仕様書」とテキスト比較(diff)を行うことで、どの機能が追加・変更されたかを浮き彫りにできます。
これは特に、担当者が退職してブラックボックス化した機能の仕様を復元する際に極めて強力な手法です。
まとめ
プロダクションコードと設計書の差異は、開発現場の生産性と品質を蝕む静かなる脅威です。しかし、生成AI技術の発展により、これまで人手では不可能だった「意味レベルでの自動検証」ができるようになりました。
例えば、本レポートで紹介した手法を次のように段階的に導入することも可能です。
Step.1: Cursor等のAIエディタを導入し、実装時に設計記述の有無を都度確認する習慣をつける。
Step.2: 設計書とコードの整合性チェックを行うスクリプト(LangChain等を利用)を作成し、定期的に実行する。
Step.3: CI/CDパイプラインに組み込み、プルリクエスト時に「設計書との乖離リスク」を自動でコメントするワークフロー(DocOps)を構築する。
「設計書は書いたら終わり」ではなく、コードと共に生き続ける資産として管理するために、テクノロジーによる支援は不可欠です。
FAQ generated by AI
一般的なコンシューマー向けの無料版を使用すると学習データとして利用されるリスクがあります。API経由の利用(OpenAI APIのZero Data Retention設定など)や、Azure OpenAI Serviceなどのエンタープライズ契約、あるいはローカルLLMを使用することで、データプライバシーを確保する必要があります。
そのままではLLMでの解析精度が落ちます。Pythonのライブラリ(pandasやopenpyxl)を使ってExcel内のテキストを抽出し、MarkdownやJSON形式などの構造化テキストに変換してからLLMに処理させる前処理が必要です。
全量を一度に比較するのはコストと時間の面で現実的ではありません。変更があったファイルやモジュールに対象を絞って差分検知を行うか、夜間バッチでモジュールごとに順次処理するような運用設計が必要です。
はい、あります。AIは「矛盾がある」と嘘をつくこともあれば、ある矛盾を見落とすこともあります。AIの出力はあくまで「レビュー支援」として扱い、最終的な判断は人間が行う必要があります。
ツール(Cursor等)の利用料に加え、API利用料(トークン課金)がかかります。設計書とコード全量を毎日比較すると高額になるため、差分のみを比較するなどの最適化がコスト抑制の鍵となります。
