
生成AIとMCPサーバーを用いた大規模システム開発における影響範囲調査手法
Summary generated by AI
- Serena MCPはLSPと連携してコードをシンボルレベルで意味的に理解するため、grep等のキーワード検索では発見困難な間接的依存関係も高精度に特定できる
- Spring Frameworkを題材とした検証では、Serena MCPありの方が網羅性・粒度・開発コンテキストの理解度すべてにおいて優れた影響範囲調査結果を示した
- MCPサーバー(Serena・Sequential Thinking・DBHub等)を組み合わせることで、コード・DB・ビジネスロジックを含む広範な影響範囲調査の自動化が期待できる
はじめに
AI駆動開発(AI-Driven Development)は、コードの自動生成やテストの自動化により、開発プロセスの効率を格段に向上させる可能性を秘めています。 しかし、その強力な能力を大規模かつ複雑なシステム開発に適用するには、まだ多くの課題が存在します。特に深刻なのが、ある機能の改修が、その機能に依存している他の多数のモジュールとの整合性を破綻させてしまう「影響範囲」の問題です。
従来の開発では、この影響範囲の特定は開発者の経験や知識に大きく依存しており、多大な時間とコストを要するだけでなく、見落としによるバグの温床ともなっていました。
本記事では、この課題に対する新たなアプローチとして、生成AIとMCP(Model Context Protocol)サーバーを組み合わせ、改修に伴う影響範囲を網羅的かつ効率的に調査する手法を紹介します。
AI駆動開発とは
AI駆動開発とは、ソフトウェア開発のライフサイクル全体(要件定義、設計、実装、テスト、保守)において、人工知能(AI)、特に機械学習(ML)や大規模言語モデル(LLM)を積極的に活用し、プロセスの一部または全体を自動化・支援する開発アプローチです。
従来の開発プロセスが主に手動であったのに対し、AI駆動開発ではコードの自動生成、テストケースの作成、バグの検出、リファクタリング提案などをAIが担います。 これにより、開発者はより創造的なタスクに集中でき、開発スピードの向上、品質の均一化、コスト削減といった多くのメリットが期待されています。 GitHub Copilotのような「AIペアプログラマ」の登場は、このアプローチの実用性を広く知らしめました。
MCPサーバーとは
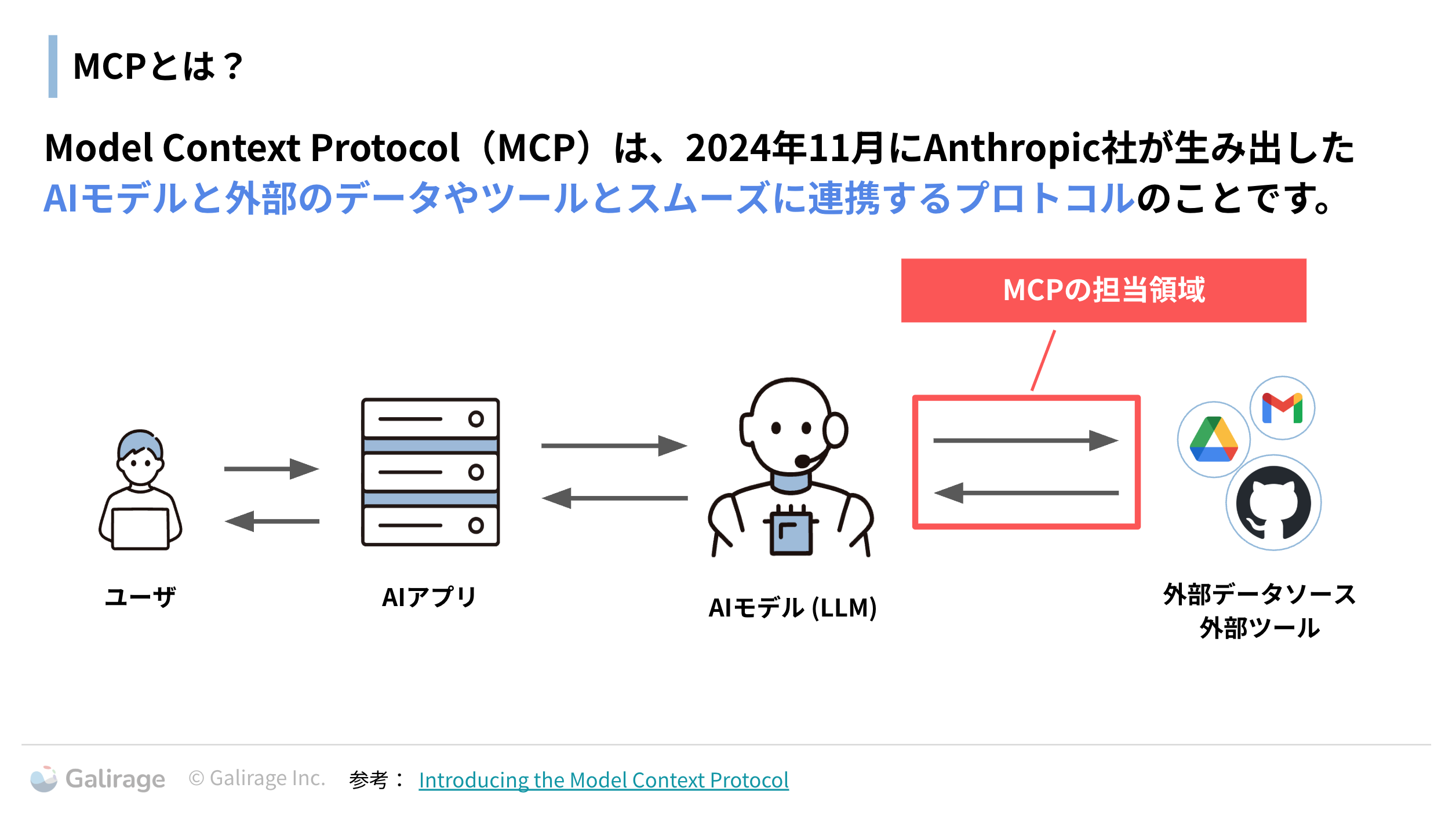
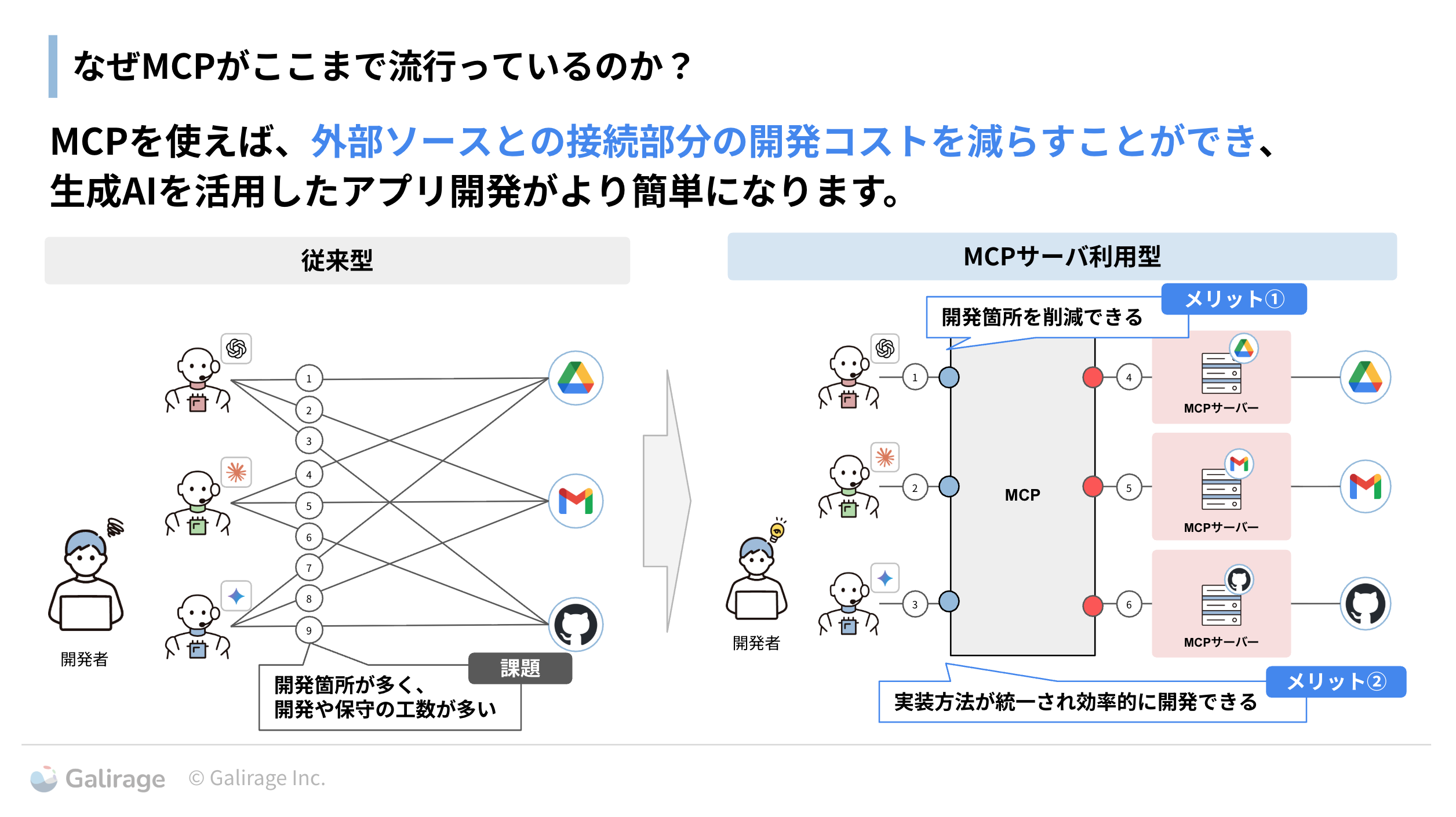
MCPは、2024年11月にAnthropic社が生み出した、AIモデルと外部のデータやツールとをスムーズに連携させるためのオープンな標準プロトコルです。 MCPを利用することで、AIはデータベース、API、ファイルシステムといった多様な外部ソースと、統一された方法で対話できます。データソースそれぞれと連携するために必要だった開発が不要になるため、開発コストが大幅に削減され、生成AIを活用したアプリケーション開発がより簡単になることから広く注目を集めています。
ここでは、大規模プロジェクトでのAI駆動開発に活用可能な3種類のMCPサーバーを紹介します。 また、特に「Serena MCP」については、後半部分で実際に大規模プロジェクトでの活用のモデルケースを示します。
Serena MCPとは
Serena MCPは、LLM(大規模言語モデル)を、単なるコード補完ツールから「完全な機能を備えたコーディングエージェント」へと進化させるためのオープンソースMCPサーバーです。
GitHub CopilotやCursorといった一般的なコーディングツールが、主にファイル単位でのテキスト補完や生成を得意とするのに対し、Serena MCPはLSP(Language Server Protocol)と連携することで、コードを単なるテキストとしてではなく、シンボル(クラス、メソッド、変数など)の集合体として意味的に理解します。
この特長により、影響範囲調査においては以下のようなメリットが生まれます。
高精度な探索: AIがファイルを横断して特定の関数の定義元や参照元をピンポイントで特定できます。これにより、grepのようなキーワード検索では見つけられない、あるいはノイズが多くなるような間接的な依存関係も正確に洗い出すことが可能です。
トークン消費の抑制: コードベース全体を読み込むのではなく、LSPから得られるシンボル情報をもとに必要な部分だけをAIに渡すため、LLMのコンテキストウィンドウを効率的に利用でき、大規模なコードベースでも高速に動作します。
エージェントによる自律的な操作: 「この関数をリファクタリングして、すべての呼び出し元を修正する」といった抽象的な指示を理解し、自律的にコードの検索、編集、検証といった一連のタスクを実行できます。
Sequential Thinking MCPとは
Sequential Thinking MCP Serverは、複雑な問題を解決可能なステップに分解し、構造化された思考プロセスを通じてAIにタスクを実行させるためのツールです。
一般的なコーディングツールへの指示が一度きりのやりとりで完結することが多いのに対し、このMCPはAIの思考プロセスそのものを支援します。影響範囲調査のような複雑なタスクにおいては、以下のような利点があります。
体系的な調査: 「まず類似の機能を持つ関数を探し、次に見つかった関数の利用箇所をリストアップし、最後にそれらの実装を比較してリファクタリング対象を洗い出す」といった多段階の調査を、AIが論理的な順序で実行できます。
思考の分岐と評価: 複数のアプローチや仮説を並行して検討し、それぞれの長所と短所を評価しながら、より最適な解決策を見つけ出すことが可能です。
プロセスの透明性: AIがどのような手順で結論に至ったのかが明確になるため、結果の信頼性を検証しやすくなります。
DBHubとは
DBHubは、PostgreSQL, MySQL, SQL Server, SQLiteなど、多様なデータベースへの接続を可能にする汎用のデータベースゲートウェイとして機能するMCPサーバーです。 これにより、AIエージェントは標準化されたインターフェースを通じて、さまざまなデータベースのスキーマ情報を探索したり、データを操作したりできます。
一般的なコーディングツールでは、データベースとの連携はプラグインや拡張機能に依存することが多く、セットアップが煩雑になりがちです。DBHubを利用することで、影響範囲調査において以下のようなメリットが期待できます。
データベーススキーマ変更の影響調査: 特定のテーブルやカラムの変更が、アプリケーションコードのどの部分に影響を与えるかを、SQLクエリやORM(Object-Relational Mapping)のコードを解析して特定できます。
データに依存したロジックの解析: コード内のロジックだけでなく、データベースに格納されている実際のデータを参照しながら、その挙動や影響を調査できます。
統一的なインターフェース: データベースの種類を問わず、同じ方法でAIがデータベースにアクセスできるため、複数の異なるデータベースを利用する大規模システムでも効率的な調査が可能です。
Spring Frameworkに対する生成AIとMCPサーバーを用いた影響範囲調査の技術検証
テーマ説明
今回の検証では、Javaで開発されている大規模かつ著名なオープンソース・ソフトウェア(OSS)である「Spring Framework」を題材とします。 Spring Frameworkは、エンタープライズJavaアプリケーション開発においてもよく使われるフレームワークであり、その内部は複雑な依存関係を持つ多数のモジュールで構成されています。
検証方法(概要)
今回は、Spring Frameworkに新機能を追加実装する、というシナリオで検証を行います。 具体的には、既存のクラスに新しいメソッドを追加し、そのメソッドを利用して既存コードをリファクタリングするという状況です。 AIには、そのリファクタリング対象となりうる影響範囲を調査させます。
<具体的な検証シナリオ>
追加する機能:
StringUtilsクラスに、キャメルケース(camelCase)の文字列をスネークケース(snake_case)に変換するtoSnakeCase(String str)という新しいメソッドを追加する、という設定にします。
**AIに調査させる内容:**1. toSnakeCaseと似たような処理を独自に実装している箇所を網羅的に調査する。
また、既に似たような共通関数などが存在しないかも調査する。
上記の通り、今回の改修内容自体はごくシンプルなものです。 しかし、大規模なプロジェクトでこれと同様の改修を行う際は実務上陥りやすい罠があります。 今回のように汎用関数を追加するケースでは、コードベース全体をDRYに保つために、同様の処理を行っている既存の実装箇所を追加した関数で置き換えることが望ましいです。 しかし、こういった箇所は大きなコードベースだとどうしても見落としがちです。 それを今回AIとSerena MCPサーバーの力を借りて効率的に発見していきます。
検証手順
今回の検証の手順は以下の通りです。
Cursor(AI駆動開発に特化したIDE)にSerena MCPサーバーを追加し、有効化します。
git cloneコマンドでSpring Frameworkのソースコードを取得しました。Cursorのエージェントモードで、以下の指示を与えます。
CursorにSerena MCPサーバーを追加
今回は、CursorからAIエージェントに自然言語で指示を出す形で改修範囲の調査を行いました。 まず、Cursorの設定ファイルを下記のように編集して、Serena MCPサーバーを利用できるようにしました。
{
"mcpServers": {
"serena": {
"command": "uvx",
"args": [
"--from",
"git+https://github.com/oraios/serena",
"serena-mcp-server",
"--context",
"ide-assistant"
]
}
}
}なお、MCPサーバーの起動時、具体的にどのToolが使われたかの情報は、標準的な設定だと
http://localhost:24282/dashboard/index.htmlにブラウザでアクセスすることで確認することができます。 ※下記は上記にアクセスすると表示されるSerena MCPのダッシュボード画面です。
Spring Frameworkのソースコードを取得
次に、Spring Frameworkのソースコードを取得します。 こちらは単純に、下記コマンドを実行することでcloneしてくることが出来ます。
git clone git@github.com:spring-projects/spring-framework.gitclone後は、プロジェクトのディレクトリをcursorで開いておきます。
Cursorに指示出し
さて、後はCursorでAI Paneを開き、Agentモードで下記のような指示を出しました。
このコードベースのStringUtilsクラスに、キャメルケース(camelCase)の文字列をスネークケース(snake_case)に変換するtoSnakeCase(String str)という新しいメソッドを追加したいです。
1. 追加後に既存のコードをこの関数を使ってリファクタしたいので、似たような処理をベタ書きしているところをリストアップしてください。
2. また、既に似たような共通関数などが存在しないかも調査してください。この検証を、「Serena MCPを有効にした場合」と「無効にした場合(Cursorの標準AI機能のみ)」の2パターンで実施し、結果を比較します。
検証結果
以下に、Serena MCPの有無によるAIの調査結果を示します。
項目 | Serena MCPあり | Serena MCPなし |
網羅性 | 類似関数3件、使用箇所を5件特定。直接のリファクタ対象ではない関連実装も検出。 | 類似関数を3件、使用箇所を3件特定。 |
粒度 |
|
|
理解度 |
| コードの機能的な類似性のみを指摘。 |
出力 | 重複実装箇所を2件提示し、うち1件は注意が必要であると明記。 | 重複実装箇所を1件提示するに留まる。 |
【Serena MCPあり の場合】
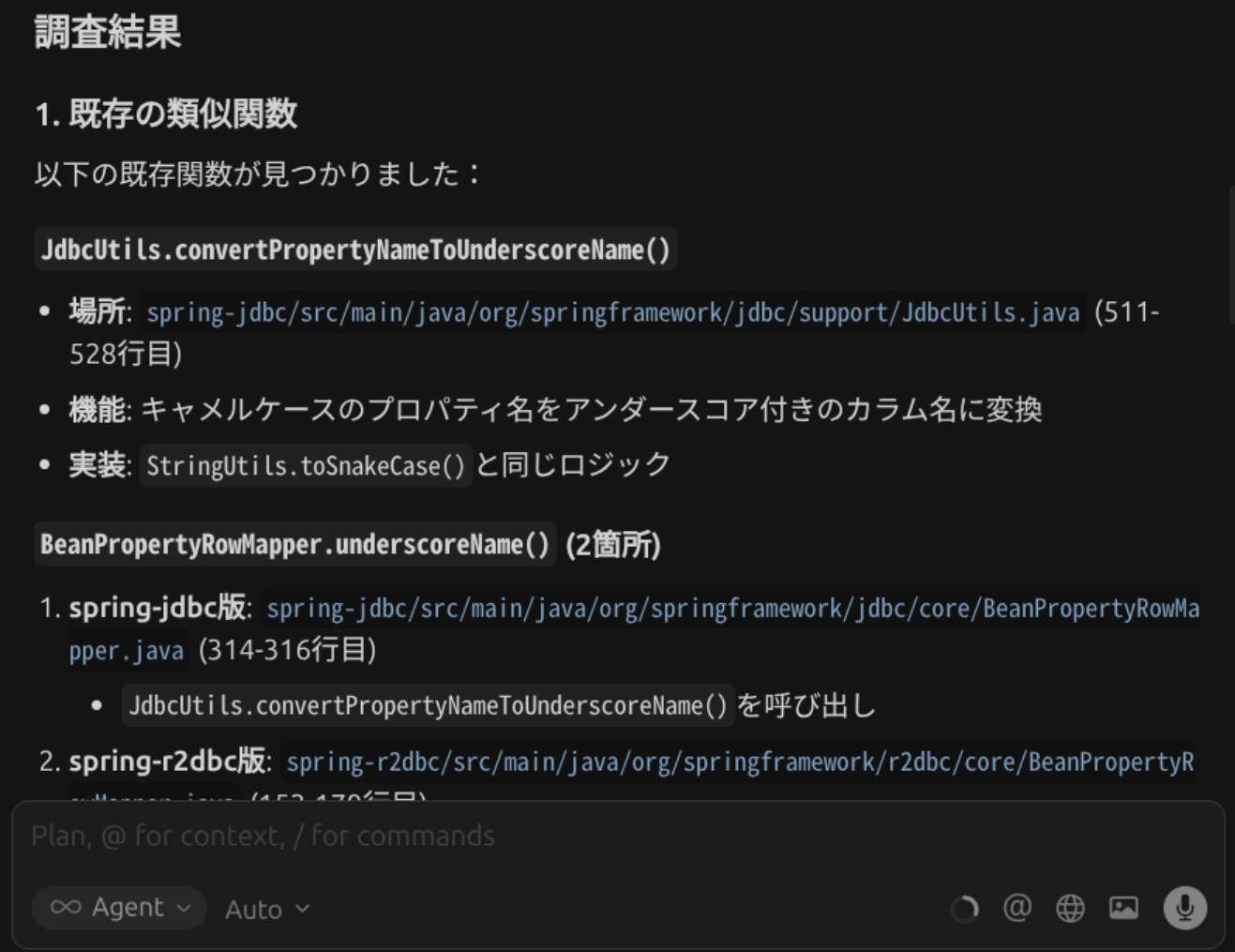
Serena MCPを有効にした場合、指示に対してAIがSerena MCPのfind symbolなどのツールを使用し、最終的に下記の内容を出力しました。
後に示す、Serena MCPなしの場合よりも網羅性と具体性が高いことが分かります。
調査結果(AI出力を抜粋)
1. 既存の類似関数
以下の既存関数が見つかりました:
`JdbcUtils.convertPropertyNameToUnderscoreName()`
場所: `spring-jdbc/src/main/java/org/springframework/jdbc/support/JdbcUtils.java` (511-528行目)
機能: キャメルケースのプロパティ名をアンダースコア付きのカラム名に変換
実装: `StringUtils.toSnakeCase()`と同じロジック
`BeanPropertyRowMapper.underscoreName()` (2箇所)
`spring-jdbc`版:
場所: `spring-jdbc/src/main/java/org/springframework/jdbc/core/BeanPropertyRowMapper.java` (314-316行目)
実装: `JdbcUtils.convertPropertyNameToUnderscoreName()`を呼び出し
`spring-r2dbc`版:
場所: `spring-r2dbc/src/main/java/org/springframework/r2dbc/core/BeanPropertyRowMapper.java` (153-170行目)
実装: 独自実装(同じロジック)
2. ベタ書きの実装箇所(リファクタ対象)
以下の箇所で、キャメルケースからスネークケースへの変換がベタ書き、または類似処理として実装されています。
重複実装(リファクタ推奨)
重複実装(ただし注意が必要)
3. 使用箇所(リファクタ候補)
上記の関数は以下の箇所で使用されています。
`spring-jdbc/src/main/java/org/springframework/jdbc/core/BeanPropertyRowMapper.java` (314行目)
`spring-jdbc/src/main/java/org/springframework/jdbc/core/SimplePropertyRowMapper.java` (138行目)
`spring-jdbc/src/main/java/org/springframework/jdbc/core/DataClassRowMapper.java` (123行目)
`spring-r2dbc/src/main/java/org/springframework/r2dbc/core/BeanPropertyRowMapper.java` (115行目)
`spring-r2dbc/src/main/java/org/springframework/r2dbc/core/DataClassRowMapper.java` (107行目)
4. その他の関連実装(リファクタ対象外)
`Constants.propertyToConstantNamePrefix()`: 大文字定数名への変換(目的が異なる)
`Conventions.attributeNameToPropertyName()`: ハイフン区切りからキャメルケースへの変換(逆方向の処理)【Serena MCPなし の場合】
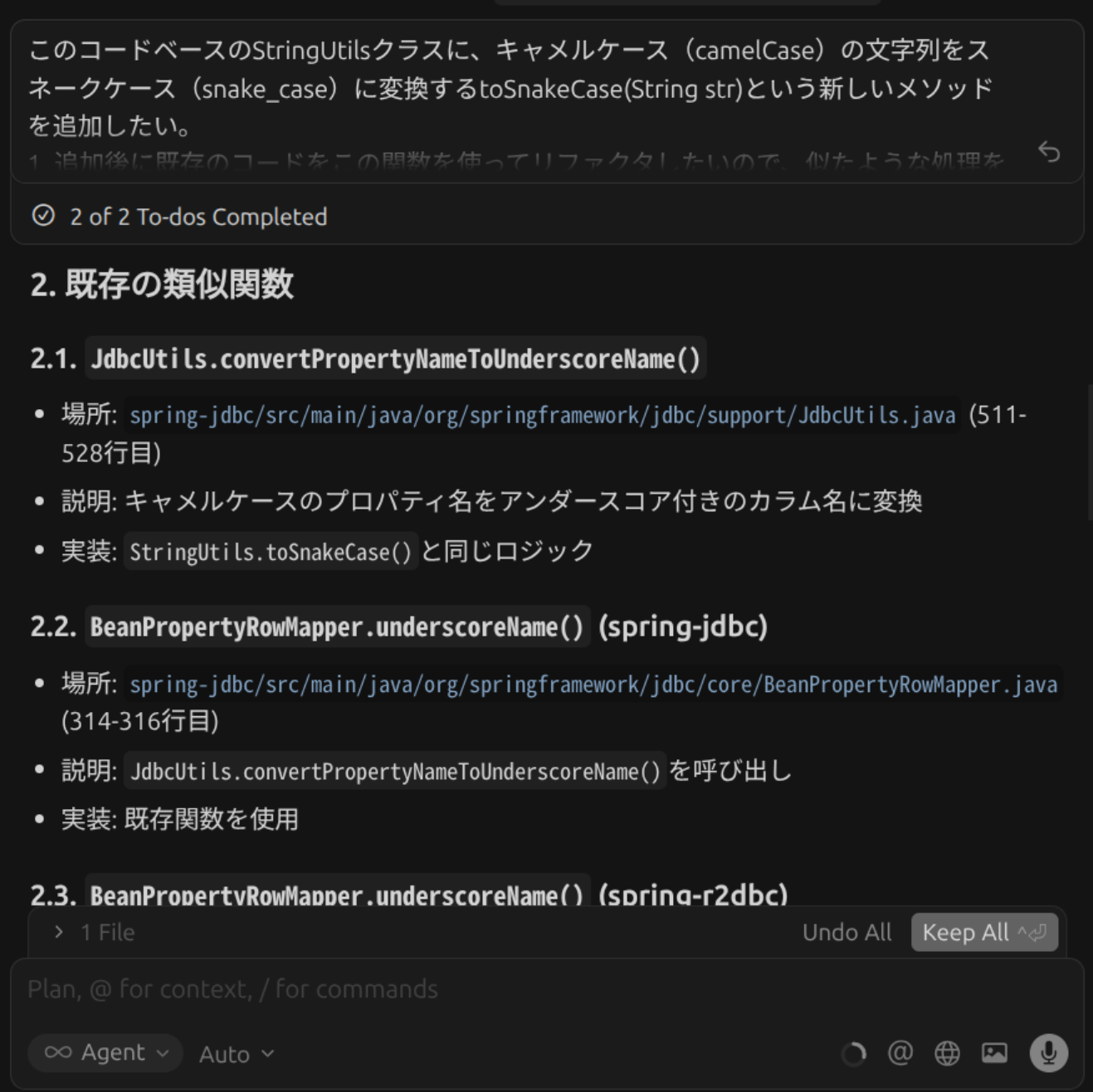
Serena MCPを無効にした場合、Cursorの標準AI機能のみで同様の指示を与えたところ、下記の内容が出力されました。 こちらも有用ではありますが、Serena MCPありの場合と比較すると、網羅性や具体性にやや欠けることが分かります。
調査結果(AI出力を抜粋)
1. 既存の類似関数
`JdbcUtils.convertPropertyNameToUnderscoreName()`
場所: `spring-jdbc/src/main/java/org/springframework/jdbc/support/JdbcUtils.java` (511-528行目)
説明: キャメルケースのプロパティ名をアンダースコア付きのカラム名に変換
実装: `StringUtils.toSnakeCase()`と同じロジック
`BeanPropertyRowMapper.underscoreName()` (spring-jdbc)
場所: `spring-jdbc/src/main/java/org/springframework/jdbc/core/BeanPropertyRowMapper.java` (314-316行目)
説明: `JdbcUtils.convertPropertyNameToUnderscoreName()`を呼び出し
実装: 既存関数を使用
`BeanPropertyRowMapper.underscoreName()` (spring-r2dbc)
場所: `spring-r2dbc/src/main/java/org/springframework/r2dbc/core/BeanPropertyRowMapper.java` (153-170行目)
説明: キャメルケースをアンダースコア名に変換
実装: ベタ書き
2. ベタ書きの箇所(リファクタ対象)
`spring-r2dbc/src/main/java/org/springframework/r2dbc/core/BeanPropertyRowMapper.java`
行: 153-170
内容: `underscoreName()`がベタ書きで実装されています。
3. 使用箇所
以下の箇所で既存の類似関数が使用されています。
`spring-jdbc/src/main/java/org/springframework/jdbc/core/SimplePropertyRowMapper.java` (138行目)
`spring-jdbc/src/main/java/org/springframework/jdbc/core/DataClassRowMapper.java` (123行目)
`spring-r2dbc/src/main/java/org/springframework/r2dbc/core/DataClassRowMapper.java` (107行目)考察
検証結果を比較すると、Serena MCPを有効にした場合に、より網羅的で質の高い影響範囲調査ができていることが分かります。
情報の網羅性と正確性の向上:
Serenaなしの場合でも主要な類似実装は発見できていますが、Serenaありの場合は、spring-jdbc版とspring-r2dbc版のBeanPropertyRowMapper.underscoreName()の実装の違い(片方は共通関数呼び出し、もう片方は独自実装)まで正確に特定しています。これは、Serenaがコードの表面的なテキストだけでなく、関数呼び出しの依存関係まで解析していることを示唆しています。
構造化と分類の質:
Serenaありの結果は、「既存の類似関数」「ベタ書きの実装箇所」「使用箇所」「リファクタ対象外」と、開発者の意図を汲んだ形で情報が明確に分類・構造化されています。これにより、開発者はどこから手をつければよいかを迅速に判断できます。一方、Serenaなしの結果も分類はされていますが、粒度が粗く、情報の関連性を読み解くのに時間がかかります。
開発コンテキストの深い理解:
特筆すべきは、Serenaありの結果がJdbcUtils.convertPropertyNameToUnderscoreName()について「既に公開APIのため、互換性を考慮」という、リファクタリングにおける重要な注意点を指摘している点です。これは、AIが単にコードのロジックを比較するだけでなく、そのメソッドが持つ責務や外部への影響といった、より高度な開発コンテキストを理解していることを示しています。
これらの差異から、Serena MCPを介することでAIはコードベース全体を意味的に理解し、より高度な静的解析に基づいた調査が可能になると結論付けられます。これは、大規模で複雑なシステムにおける影響範囲調査の精度と効率を劇的に改善する可能性を秘めています。
まとめ
本記事では、生成AIとMCPサーバー、特にSerena MCPを組み合わせて大規模システム開発における機能改修の影響範囲を調査する手法を提案し、その有効性をSpring Frameworkを題材とした技術検証によって示しました。
検証結果から、Serena MCPを用いることで、AIはコードの依存関係や意味的文脈を深く理解し、単なるキーワード検索ベースの調査では得られない、網羅的かつ構造化された精度の高い分析結果を提供できることが明らかになりました。
AI駆動開発が進化を続ける中で、今回紹介したようなMCPサーバーを介したAIエージェントとの連携は、開発者が複雑なコードベースと対峙する際の強力な武器となります。これにより、影響範囲の見落としによるバグのリスクを低減し、より安全で効率的なシステム改修が可能になるでしょう。今後の展望として、さらに多様なMCPサーバー(例えばDBHubやSequential Thinking MCP)を組み合わせることで、コードだけでなくデータベースや複雑なビジネスロジックまで含めた、より広範な影響範囲調査の自動化が期待されます。
FAQ generated by AI
はい、Serena MCPはLSP(Language Server Protocol)と連携する仕組みのため、Python、TypeScript、Go、Rustなど、LSPが整備されている多くの主要言語で利用可能です。
grep等のキーワード検索では見つけにくい間接的な依存関係を発見できる点や、静的解析ツールのような固定ルールではなく、「似た処理を探してリファクタリング案を出して」といった抽象的な指示に対して文脈を理解して回答できる点が大きな違いです。
紹介されているSerena MCPやDBHubなどはオープンソースで提供されており、無料で使用可能です。ただし、利用するIDE(Cursorなど)やLLM自体には別途利用料がかかる場合があります。
MCPサーバー自体はローカル環境等で動作させることができますが、解析のためにコード断片やプロンプトがLLMプロバイダに送信される点は通常のAIツール利用時と同様です。企業で利用する場合は、各ツールのデータプライバシー設定や組織のポリシーを確認することをお勧めします。
